

Gallery
Year 2022

CMS Research Sharing Seminar 2022
Research Talk by Invited Speaker from Universiti Putra Malaysia
Date
25 March 2022 (Friday)
Time
2.00pm – 3.00pm
Platform
Microsoft Teams
Speaker
Prof. Dr. Leong Wah June
Department of Mathematics, Faculty of Sciences
Universiti Putra Malaysia
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: In this talk, we first introduce and motivate the application of sparse optimization in wide variety of fundamental applications. A general proximal alternating linearized (PAL) method for solving a broad class of sparse optimization problems involving L0-norm is proposed. Building on the Kurdy-Lojasiewicz property, a brief convergence analysis is established. We then demonstrate the applicability of the PAL method in solving some real-life problems such as those in sparse optimal control of large-scale interconnected networks, portfolio optimization and image restoration.

Research Talk by Invited Speaker from Universiti Teknologi MARA (UiTM)
Date
24 June 2022 (Friday)
Time
3.00pm – 4.00pm
Platform
Microsoft Teams
Speaker
Prof. Isamiddin Rakhimov
Faculty of Computer and Mathematical Sciences
Universiti Teknologi MARA (UiTM)
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: The talk devoted to the classification problem of finite-dimensional algebras. We review the general strategy applied so far. Then the classification problem of Lie algebras and certain classes of algebras closely related to the class of Lie algebras will be focused on. These classes of algebras wee introduced by J.L. Loday in 1994. We show links between these classes of algebras and provide the latest results on their classification problem in low dimensions.

Research Talk by Invited Speaker from Universiti Putra Malaysia (UPM)
Date
29 September 2022 (Thursday)
Time
3.00pm – 4.00pm
Platform
Microsoft Teams
Speaker
Prof Madya Dr. Siti Nur Iqmal Binti Ibrahim
Department of Mathematics and Statistics, Faculty of Science
Universiti Putra Malaysia
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: The basis of options has been the vanilla options, and many have studied extensions of this option to construct other options, called the exotic options, to attract investors. One such option is the power options. With its higher leverage with every change in the underlying asset, power options are deemed to be more profitable than the vanilla options.
In this work, we study pricing models for European-style power call options and a modified version of this option. First, we present the fast Fourier transform (FFT) option pricing model for power call options, and also apply the Monte Carlo simulation (MCS) to compare the efficiency between these two pricing models. Then, we present a pricing formula for power call options that includes a barrier, which is called the power down-barrier options. We also show that there exists a power put-power call parity relationship, and a transformation between the underlying asset and the power contract. This study is within the Black0Scholes environment.
Finally, we run numerical experiments where we first compare the FFT and MCS for pricing the power call options, and then we compare the prices between power call options and power down-barrier options.

Research Talk by Invited Speaker from The Hong Kong Polytechnic University
Date
28 July 2022 (Thursday)
Time
3.00pm – 4.00pm
Platform
Microsoft Teams
Speaker
Prof. Yiu Ka-Fai, Cedric
Department of Applied Mathematics
The Hong Kong Polytechnic University
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: For signal processing, multi-sensors are often deployed in order to enhance signal quality in various ways. In general, beamforming technique can be applied via an array of sensors to enhance the required signal via spatial filtering. Designing better beamformers for different scenarios is essential when the sensor distribution and the environment has changed. Optimization plays an important role in the improvement process. In this talk, we will discuss some advances in the optimal design of multi-dimensional broadband beamforming system. We review on various approaches and discuss some of the performance issues. Different optimization models will be considered. In addition to optimizing filter coefficients, we found that the geometric configuration of the array is important for the accuracy of the designs. In view of this, microphone locations can be optimized together with the filter coefficients and the overall problem is formulated as a non-convex optimization problem. When wireless sensors are operated, it is possible to design the beamformer in a distribution manner. Furthermore, it is possible to employ only a subset of the sensors to satisfy a specified performance requirement. In this way, the complexity of the beamformers can be greatly reduced. We will illustrate by several examples the proposed methods.

Research Talk by Invited Speaker from Heriot-Watt University, Malaysia
Date
26 August 2022 (Friday)
Time
2.30pm – 3.30pm
Platform
Microsoft Teams
Speaker
Dr. Mahendran Shitan
School of Mathematical and Computer Science
Heriot-Watt University, Malaysia
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: In this paper, we extend the idea of Gegenbauer process in the spatial domain by introducing a more general parameter and call this model as Spatial Gegenbauer Autoregressive (SGAR (1,1)) model. The spectral density and autocovariance functions of the model are introduced. The Yajima estimators of the Gegenbauer parameters, the log-periodogram regression estimators of the memory parameters and the Whittle's estimators of all parameters are discussed. The performance of these estimators is evaluated through a simulation study.

Research Talk by Invited Speaker from International Islamic University Malaysia (IIUM)
Date
31 October 2022 (Monday)
Time
3.00pm – 4.00pm
Platform
Microsoft Teams
Speaker
Ts. Dr. Hafizah Noor Bt Isa
Department of Physics, Kulliyyah of Science
International Islamic University Malaysia (IIUM)
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: Einstein's theory of general relativity predicted the existence of gravitational waves, but it was only in 2015 that they were finally detected by scientists working at LIGO laboratories. This discovery has been heralded as one of this century's greatest scientific breakthroughs and may have implications for our understanding not just dark matter or energy distributed throughout space-time- but time itself.

Research Talk by Invited Speaker from Taylor's University
Date
29 April 2022 (Friday)
Time
2.00pm – 3.00pm
Platform
Microsoft Teams
Speaker
Associate Professor Dr. Chang Yun Fah
Actuarial Studies Program, School of Accounting and Finance, Faculty of Business and Law
Taylor's University
Organizer/
Centre for Mathematical Sciences (CMS)
Abstract: The functional relationship model (also called measurement error model or error in variables model) is a model extended from the classical linear regression where errors are assumed in both the X and Y variables which has been explored since the 19th century by Adcock (1878). Many further studies were then conducted to p-dimension of X and Y with single slope and uncorrelated variables. In this talk, we discuss a generalized version of Chang et al. (2010) works by allowing multicollinearity among the dimensions under study. The fundamental derivations on the model which includes multicollinearity to obtain the close form equations of the parameters and the properties of the estimated parameters will be discussed. At the end of the talk, simulation results and numerical example will also be presented.
Year 2021
Virtual Visit of External Examiner
Date: 6th & 7th December 2021
Platform: Microsoft Teams
Programme: Bachelor of Science (Honours) Applied Mathematics with Computing
External Examiner: Prof. Dr. Huang Huang-Nan (Tunghai University, Taiwan)
Programme: Bachelor of Science (Honours) Financial Mathematics
External Examiner: Prof. Dr. Yang Hailiang (The University of Hong Kong)
Opening Meeting

Meeting with Staff
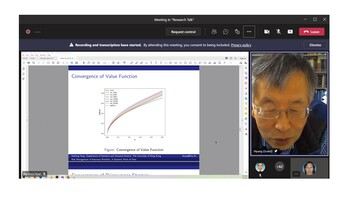
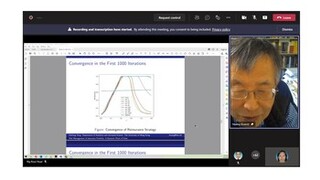
Research Talk by Prof. Dr. Yang Hailiang
Optimal Insurance Strategies: A Hybrid Deep Learning Markov Chain Approximation Approach
Date
6 December 2021 (Monday)
Time
2.00pm – 3.00pm
Platform
Microsoft Teams
Speaker
Prof. Dr. Yang Hailiang
Department of Statistics and Actuarial Science
The University of Hong Kong
Hong Kong
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
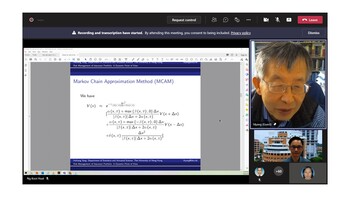
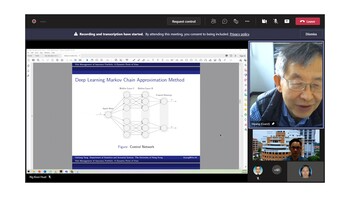
This paper studies deep learning approaches to find optimal reinsurance and dividend strategies for insurance companies. Due to the randomness of the financial ruin time to terminate the control processes, a Markov chain approximation-based iterative deep learning algorithm is developed to study this type of infinite-horizon optimal control problems. The optimal controls are approximated as deep neural networks in both cases of regular and singular types of dividend strategies. The framework of Markov chain approximation plays a key role in building the iterative equations and initialization of the algorithm. We implement this self-learning approach to approximate the optimal strategies and compare the learning results with existing analytical solutions. Satisfactory computation efficiency and accuracy are achieved as presented in numerical examples.
Date | 6 December 2021 (Monday) |
Time | 2.00pm – 3.00pm |
Platform | Microsoft Teams |
Speaker | Prof. Dr. Yang Hailiang Department of Statistics and Actuarial Science The University of Hong Kong Hong Kong |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
This paper studies deep learning approaches to find optimal reinsurance and dividend strategies for insurance companies. Due to the randomness of the financial ruin time to terminate the control processes, a Markov chain approximation-based iterative deep learning algorithm is developed to study this type of infinite-horizon optimal control problems. The optimal controls are approximated as deep neural networks in both cases of regular and singular types of dividend strategies. The framework of Markov chain approximation plays a key role in building the iterative equations and initialization of the algorithm. We implement this self-learning approach to approximate the optimal strategies and compare the learning results with existing analytical solutions. Satisfactory computation efficiency and accuracy are achieved as presented in numerical examples.
Thank you for the informative sharing!

Meeting with Students (AM)
Meeting with Students (FM)

Exit Meeting
Virtual Visit of External Examiner for Bachelor of Science (Honours) Actuarial Science
Prof. Dr. Yam Sheung Chi Phillip
(The Chinese University of Hong Kong)
Date: 29th & 30th November 2021
Platform: Zoom
Opening Meeting
Meeting with Students
Meeting with Staff
Exit Meeting
Research Talk by Invited Speaker from Universiti Teknologi PETRONAS
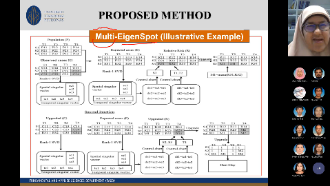
Multi-EigenSpot: A Novel Eigenspace-Based Method for Detecting Multiple Space-Time Disease Clusters
Date
21 October 2021 (Thursday)
Time
10.00am – 11.00am
Platform
Microsoft Teams
Speaker
Assoc. Prof. Dr Hanita binti Daud
Fundamental and Applied Sciences Department
Universiti Teknologi PETRONAS
Perak, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 21 October 2021 (Thursday) |
Time | 10.00am – 11.00am |
Platform | Microsoft Teams |
Speaker | Assoc. Prof. Dr Hanita binti Daud Fundamental and Applied Sciences Department Universiti Teknologi PETRONAS Perak, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
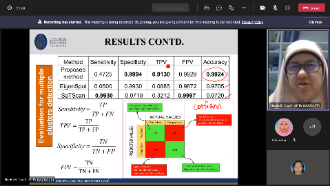
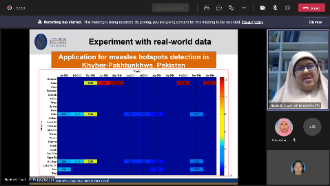
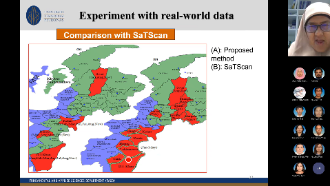
Detecting the potential space-time disease clusters is necessary for conducting surveillance and implementing disease prevention policies. In disease surveillance, space-time cluster detection aims to detect the sub-regions in the spatiotemporal space, where the observed disease count is higher than what is to be expected if no risk factor exists. The state-of-the-art method for this problem is the space-time scan statistic (SaTScan). This method is based on the Maximum Likelihood Estimation (MLE) which put some constraints on the distribution of the data such as Poisson or Gaussian counts that are valid only for the laboratory data and not necessarily valid for the non-traditional data sources. Addressing this problem, an Eigenspace-based method called an EigenSpot has been recently proposed as a nonparametric solution for space-time cluster detection. However, the main problem with the EigenSpot method is that it can detect a single cluster only and cannot be adapted for detecting multiple clusters. This is an important limitation, since multiple hotspots may have occurred in the study area, sometimes at the same level of importance. Addressing this issue, this study proposes an extension of the EigenSpot method, called a Multi-EigenSpot that is able to handle multiple hotspots by iteratively removing previously detected hotspots and re-running the algorithm until no more hotspots are found. The proposed method uses the expected disease counts as the baseline information instead of the population counts and hence allows for removing the previously detected cluster by replacing the observed counts by the respective expected counts. The proposed method approximates multiple clusters automatically through a visualization tool. In addition, the proposed method can be adapted for detecting clusters with unknown population counts which is often the case in the least developed countries. A comprehensive experimental evaluation, both on simulated and real-world datasets reveals that the proposed method not only provides a nonparametric solution to multiple clusters detection problem but also characterizes relatively higher efficiency than the state-of-the-art methods.
Thank you for the wonderful sharing!


Research Talk by Invited Speaker from Multimedia University Melaka, Malaysia
Swarm Intelligence Mimicking to Solve Complex Problems
Date
10 September 2021 (Friday)
Time
10.00am– 11.00am
Platform
Microsoft Teams
Speaker
Dr Nor Azlina Binti Ab Aziz
Faculty of Engineering and Technology
Multimedia University Melaka, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 10 September 2021 (Friday) |
Time | 10.00am– 11.00am |
Platform | Microsoft Teams |
Speaker | Dr Nor Azlina Binti Ab Aziz Faculty of Engineering and Technology Multimedia University Melaka, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
Swarm intelligence (SI) belongs to the family of computational intelligence algorithms. The algorithms from SI family are mostly inspired from nature and work based on the concept of collaboration and information sharing. Among the popular SI algorithms are Particle Swarm Optimization (PSO), Ant Colony Optimization (ACO), Artificial Bee Colony (ABC), and many others. These algorithms share the same framework but differ from each other on how the agents look for a solution which is dependent on their source of inspiration. During this session, the broad concept of SI will be discussed, followed by some of the popular SI algorithms and an example of application for solving a real-world problem. This session aims to attract the interest of new researchers in this field and as a channel of discussion among existing SI’s researchers.
Thank you for the informative sharing!

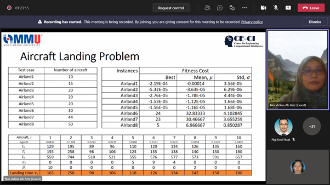
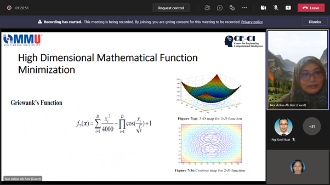
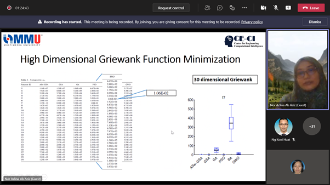
Research Talk by Invited Speaker from Universiti Tun Hussein Onn Malaysia
Curve Fitting with First-Order Linear Differential Equation
Date
20 August 2021 (Friday)
Time
10.00am– 11.00am
Platform
Microsoft Teams
Speaker
Dr Kek Sie Long
PhD, CQRM
Department of Mathematics and Statistics
Universiti Tun Hussein Onn Malaysia
Pagoh Campus, Muar, Johor, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 20 August 2021 (Friday) |
Time | 10.00am– 11.00am |
Platform | Microsoft Teams |
Speaker | Dr Kek Sie Long PhD, CQRM Department of Mathematics and Statistics Universiti Tun Hussein Onn Malaysia Pagoh Campus, Muar, Johor, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
In this talk, the curve fitting, which is handled by using the first-order linear differential equation, is discussed. For this purpose, the coefficient of proportionality is determined from the set of data points. For the constant coefficient, the measures of the central tendency, which are mean, median, and mode, are calculated. By applying these constant coefficients and the varying coefficients, the first-order linear differential equation exists and solvable. On this basis, the Euler method is applied to approximate the solution of the differential equations. For illustration, some sets of data points and their curves are observed, while the best fitting of these curves is demonstrated by using the method proposed. The results show that the performance efficiency of the method proposed is satisfied within a given tolerance. In conclusion, applying the linear differential equation to fit the curve of data points provides an effective alternative approach for the curve fitting problem.
Thank you for the educational sharing!
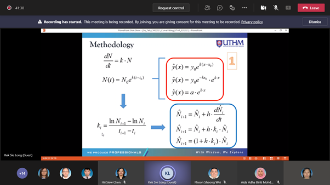
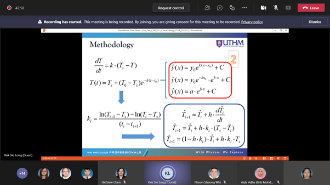
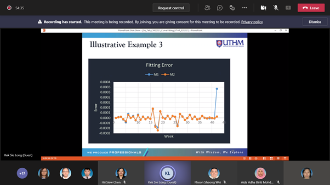
Research Talk by Invited Speaker from Universiti Sains Malaysia
Tight Bounds on the Burning Numbers of Path Forests and Spiders
Date
13 August 2021 (Friday)
Time
10.00am– 11.00am
Platform
Microsoft Teams
Speaker
Dr Teh Wen Chean
School of Mathematical Sciences
Universiti Sains Malaysia
Pulau Pinang, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 13 August 2021 (Friday) |
Time | 10.00am– 11.00am |
Platform | Microsoft Teams |
Speaker | Dr Teh Wen Chean
School of Mathematical Sciences Universiti Sains Malaysia Pulau Pinang, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
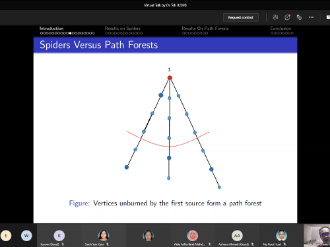
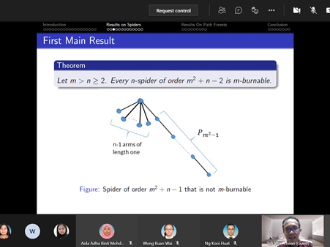
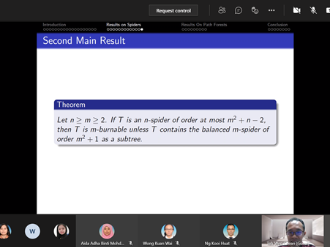
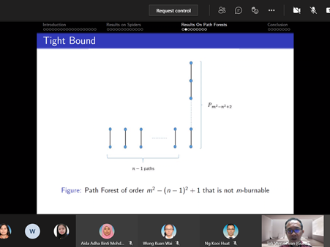
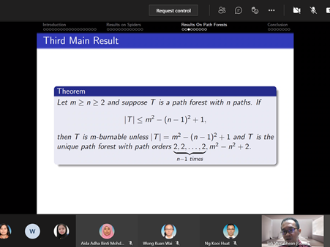
In 2016, Bonato, Janssen, and Roshanbin introduced graph burning as a discrete process that models the spread of social contagion. Although the burning process is a simple algorithm, the problem of determining the least number of rounds needed to completely burn a graph is NP-complete even for elementary graph structures like starlike trees, also called spiders. An open burning number conjecture states that every connected graph of order m2 can be burned in at most m rounds. Attempts to prove the conjecture have resulted in various upper bounds for the burning number and verification of the conjecture for various classes of graphs, including spiders. In this seminar, we will present a detailed outline about our contribution towards the burning number conjecture, which results from a collaborative work with Ta Sheng Tan. Together, we found a tight upper bound on the order of a spider for it to be burned within a given number of rounds. Our result showed that the tight bound depends on the structure of the spiders, namely the number of arms. Additionally, an analogous corresponding tight upper bound for path forests was obtained, thus completing a previously known partial result. This suggests new perspective towards the burning number conjecture via characteristics of graphs. We will end the presentation by briefly mentioning the speaker's ongoing work as appropriate. This presentation is intended to facilitate readers interested in our contribution and as an invitation for potential collaboration into this work.
Thank you for the interesting sharing!
Research Talk by Invited Speaker from Universiti Malaya
Modelling and forecasting stock volatility and return: A new approach based on quantile Rogers-Satchell volatility measure with asymmetric bilinear CARR model
Date
6 August 2021 (Friday)
Time
11.00am– 12.00pm
Platform
Microsoft Teams
Speaker
Assoc Prof Dr Ng Kok Haur
Institute of Mathematical Sciences
Faculty of Science
Universiti Malaya
Kuala Lumpur, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 6 August 2021 (Friday) |
Time | 11.00am– 12.00pm |
Platform | Microsoft Teams |
Speaker | Assoc Prof Dr Ng Kok Haur
Institute of Mathematical Sciences Faculty of Science Universiti Malaya Kuala Lumpur, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
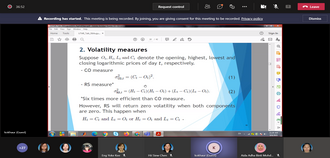
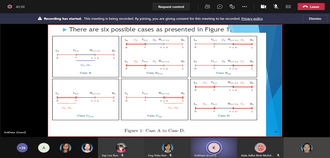
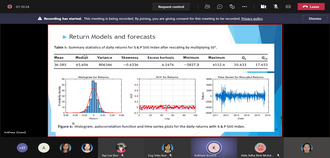
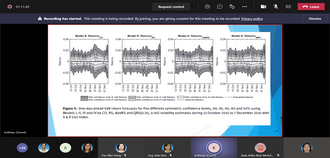
Volatility of asset prices in financial market is not directly observable. Return-based models have been proposed to estimate the volatility using daily closing prices. Recently, many new range-based volatility measures were proposed to estimate the volatility directly. This study proposes quantile Rogers-Satchell (QRS) measure to ensure robustness to extreme prices. We add an efficient term to correct the downward bias of Rogers-Satchell (RS) measure and provide scaling factors for different interquantile range levels to ensure unbiasedness of QRS. Simulation studies confirm the efficiency of QRS measure relative to the intraday squared returns and RS measures in the presence of extreme prices. To smooth out the noises, QRS measures are fitted to the conditional autoregressive range model with different asymmetric mean functions. By comparing to two realised volatility measures as proxies for the unobserved true volatility, result from Standard and Poor 500 index shows that QRS volatility estimates using asymmetric bilinear mean function provide the best in-sample model fit based on two robust loss functions. These fitted volatilities are then incorporated into return models to capture the heteroskedasticity of returns. Model with a constant mean, Student-t errors and QRS estimates gives the best-in-sample fit. Different value-at-risk (VaR) and conditional VaR forecasts based on the best return model are also provided and tested.
Thank you for the wonderful sharing!

Research Talk by Invited Speaker from Universiti Malaysia Terrengganu (UMT)
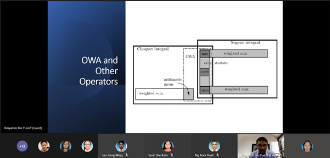
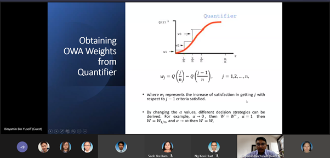
Ordered Weighted Averaging Operators: Modelling the Majority Concept based on Cardinality
Date
30 July 2021 (Friday)
Time
11.00am– 12.00pm
Platform
Microsoft Teams
Speaker
Dr. Binyamin Yusoff
Mathematical Sciences Field
Faculty of Ocean Engineering Technology and Informatics
Universiti Malaysia Terrenganu (UMT)
Terrengganu, Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 30 July 2021 (Friday) |
Time | 11.00am– 12.00pm |
Platform | Microsoft Teams |
Speaker | Dr. Binyamin Yusoff
Mathematical Sciences Field Faculty of Ocean Engineering Technology and Informatics Universiti Malaysia Terrenganu (UMT) Terrengganu, Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
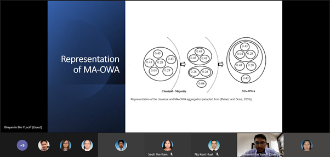
Aggregation of several input values into a single output value is crucial in numerous mathematical models. The problems of aggregation are very broad and heterogeneous. This talk will particularly focus on the ordered weighted averaging (OWA) operators, a specific topic of aggregation under the finite number of real inputs. The OWA operators are a parameterized family of mean operators. Recent developments of OWA, especially under the cardinality-dependent aggregation operators, or the so-called majority-additive OWA, will be presented. The MA-OWA operator generalizes the simple arithmetic mean, and it is known as the arithmetic mean of arithmetic means. Moreover, it can control the effect of extreme values in arithmetic mean that may cause biased results. The other variants of this aggregation operator, namely selective majority additive (SMA-OWA), selective aggregated majority (SAM-OWA) and weighted SAM-OWA with additional characteristic of cardinality relevance factor (CRF) will also be highlighted. Finally, the application of these aggregation operators in group decision-making problem will be presented to conclude this talk.
Thank you for the enlighten sharing!



Research Talk by Invited Speaker from Universiti Teknologi MARA
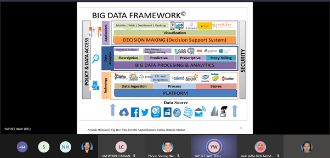
Big Data Analytics: Tools, Techniques and Applications
Date
16 July 2021 (Friday)
Time
11.00am– 12.00pm
Platform
Microsoft Teams
Speaker
Prof Dr. Yap Bee Wah
Institute for Big Data
Analytics and Artificial Intelligence (IBDAAI)
& Center of Statistical and Decision Science
Studies
Faculty of Computer and Mathematical
Sciences (FSKM)
Universiti Teknologi MARA, Shah Alam, Selangor,
Malaysia
Organizer/
Co-organizer
Department of Mathematical and Actuarial Sciences (DMAS)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 16 July 2021 (Friday) |
Time | 11.00am– 12.00pm |
Platform | Microsoft Teams |
Speaker | Prof Dr. Yap Bee Wah
Institute for Big Data Analytics and Artificial Intelligence (IBDAAI) & Center of Statistical and Decision Science Studies Faculty of Computer and Mathematical Sciences (FSKM)
Universiti Teknologi MARA, Shah Alam, Selangor,
Malaysia |
Organizer/ Co-organizer | Department of Mathematical and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
Abstract:
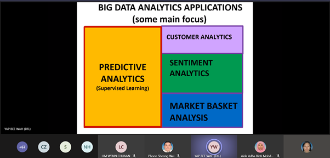
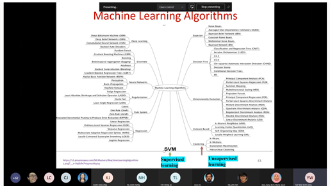
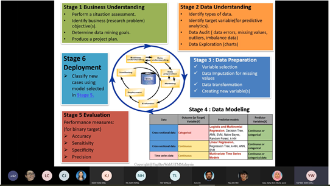
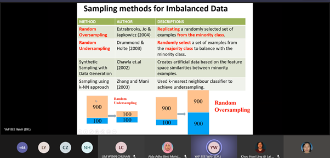
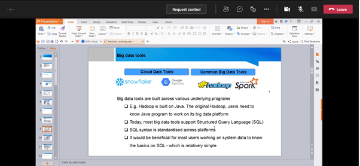
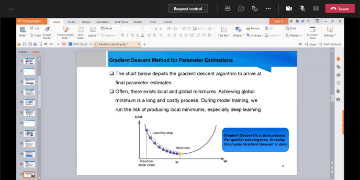
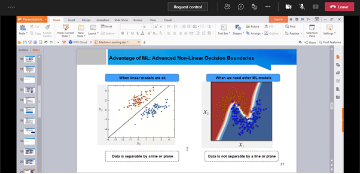
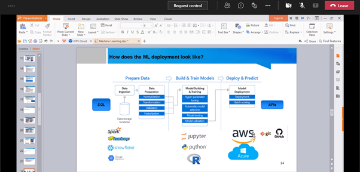
Big Data Analytics involves discovering useful and meaningful insights from structured and unstructured data. Data collection and storage is growing exponentially through the use of advanced digital technology, IoT and drones. Machine Learning and Deep Learning are useful algorithm for Big Data Analytics. This seminar covers the Big Data Analytics tools, techniques and applications in various domains. We present the Big Data Analytics framework, the popular data mining tools and machine learning algorithms for prediction and classification problem. The aim of this seminar is to share the potential applications of big data analytics for industry and academic research.
Thank you for the informative sharing!

Research Talk by Invited Speaker from Standard Chartered Bank
Machine Learning: Statistics, Technology and Application in Finance
Date
24
May 2021 (Monday)
Time
8.00pm – 10.00pm
Platform
Microsoft Teams
Speaker
Mr Gabriel
Data Strategy Manager
Standard Chartered Bank (Singapore)
Organizer/
Co-organizer
Actuarial Science Society (UTAR)
Centre for Mathematical Sciences (CMS)
Abstract:
Date | 24 May 2021 (Monday) |
Time | 8.00pm – 10.00pm |
Platform | Microsoft Teams |
Speaker | Mr Gabriel Data Strategy Manager Standard Chartered Bank (Singapore) |
Organizer/ Co-organizer | Actuarial Science Society (UTAR) Centre for Mathematical Sciences (CMS) |
Abstract:
This sharing session introduces machine learning and its application in the financial world. And, the talk includes some of the technology tools used in the machine learning world, statistics required for model building as well as the usage of computing tool on R and Python.
Thank you for the impactful sharing!
Research Talk by Invited Speaker from Universiti Tunku Abdul Rahman
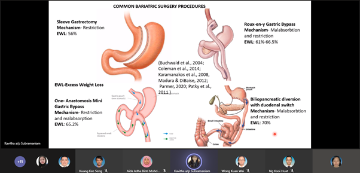
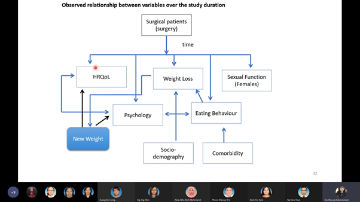
Quality of Life, Psycho-behavioural Aspects and Sexual Functioning in Obese Patients Following Weight Loss After Bariatric Surgery
Date
23 April 2021 (Friday)
Time
10.00am –11.00am
Platform
Microsoft Teams
Speaker
Dr Kavitha a/p Subramaniam
Organizer/
Co-organizer
Centre for Mathematical Sciences (CMS)
Department of Mathematical and Actuarial Sciences (DMAS)
Abstract:
Date | 23 April 2021 (Friday) |
Time | 10.00am –11.00am |
Platform | Microsoft Teams |
Speaker | Dr Kavitha a/p Subramaniam |
Organizer/ Co-organizer | Centre for Mathematical Sciences (CMS) Department of Mathematical and Actuarial Sciences (DMAS) |
Abstract:
Introduction: Bariatric surgery is currently the most durable weight loss solution for morbid obesity, which also causes improvements in comorbidity, and reduces mortality rates. Impact of the surgery on psycho-behavioural improvements and health-related quality of life (HRQoL) are equivocal. This study aims to identify the changes in HRQoL, psycho-behavioural factors and sexual function six months after bariatric surgery.
Methods:
Fifty-seven
participants (surgical patients) were recruited upon written consent. The participants
were followed up thrice:
before surgery (T0),
three months (T1) and six months (T2) after surgery,
during which, they were interviewed and with anthropometric measurements taken.
Interviews included the following: depression and anxiety screening using the
Hospital Anxiety and Depression Scale (HADS), measure of self-esteem using the
Rosenberg Self-Esteem Scale (RSES), Health-related quality of life (HRQoL)
assessment using the SF-36 instrument, which produced 8 subdomains and two
composite scores, physical component summary (PCS) and mental component summary
(MCS), Eating behaviour assessment using
the Dutch Eating Behaviour Questionnaire (DEBQ), which screened for emotional,
external and restrained eating, sexual function in women using the Female
Sexual Function Index (FSFI) instrument and sexual function in men using
International Index for Erectile Function (IIEF-5). Height and weight were
measured at every follow-up session. The Body Mass Index (BMI), Excess BMI Loss
(EBMIL) and Total Weight Loss (TWL) matrices were calculated.
Results:
Participants were predominantly women and from Malay ethnic group. The age mean age
was
39.40 ± 10.01 years; and initial BMI
was
45.46 ± 9.93 kg/m2. At T2, the EBMIL and TWL recorded
were 63.33% and 23.83% respectively. Younger age, lower emotional eating and
lower BMI/ Initial BMI predicted better TWL values after surgery. The
participants experienced improvement in all the variables studied: the rate of
anxiety (T0: 21%, T2: 3.5%) and depression (T0:
7.5%, T2: 1.8%) decreased over time. The mean self-esteem score for
the group increased over time (T0: 19.86; T2: 23.00). The
mean PCS and MCS scores improved from T0 to T2 (PCS:
42.77, 50.19; MCS: 51.59, 54.79). The emotional and external eating decreased
from baseline (2.06 and 2.86) to T1 (1.64 and 2.25) and slightly
increased at T2 (1.81 and 2.4). The restraint score increased from
2.7 at baseline to 2.93 at T1 and decreased slightly to 2.8 at T2.
Rate of female sexual dysfunction dropped from 60% at T0 to 12% at T1.
The rate of male sexual function showed an insignificant reduction from 79% at
T0 to 63.7% at T2. The psycho-behavioural and HRQoL
improvements over time were predicted by demographic characteristics, weight
and other pyscho-behavioural variables.
Conclusion:
Participants
achieved satisfactory weight loss and improvement in HRQoL and psychological
factors in the six months after bariatric surgery. The eating behaviours showed
a trend towards possible reversal of improvement and warrant further
investigation.
Key words: Weight loss,
bariatric surgery, psychology, eating behaviour, quality of life
Thank you for the educational sharing!




Research Talk by Invited Speaker from Universiti Teknologi Malaysia
COVID-19 and Mathematics
Date
26 March 2021 (Friday)
Time
10.30am –11.30am
Platform
Microsoft Teams
Speaker
Dr Nur Syarafina Binti Mohamed
Organizer/
Co-organizer
Centre for Mathematical Sciences (CMS)
Department of Mathematical and Actuarial Sciences (DMAS)
Abstract:
Date | 26 March 2021 (Friday) |
Time | 10.30am –11.30am |
Platform | Microsoft Teams |
Speaker | Dr Nur Syarafina Binti Mohamed |
Organizer/ Co-organizer | Centre for Mathematical Sciences (CMS) Department of Mathematical and Actuarial Sciences (DMAS) |
Abstract:
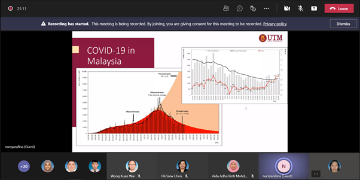
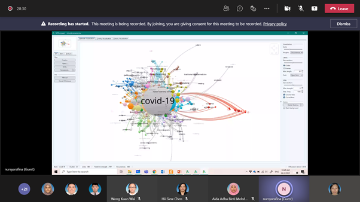
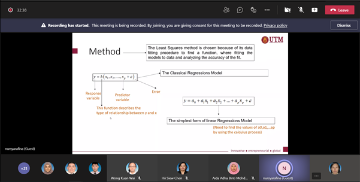
The ongoing Coronavirus Disease (COVID-19) outbreak is now declared as a pandemic by the World Health Organization (WHO). This disease began in Wuhan, China in late 2019 and is widely spread now all over the world. Progressively, Malaysia has been the leading country in Southeast Asia for this outbreak with cases more than 300,000 accumulately. Being a Mathematician, one should know how can this COVID-19 is relatable to the field. Just like our DG Dr. Noor Hisham always mentioned about the R0 value, the predicted daily cases and all the numbers have been an everyday awaiting news for Malaysia. Thus, we can conclude that, Mathematics is very significant in determining all of the conclusions because the data itself can speak of the results and the future predictions.
Thank you for the informative sharing!
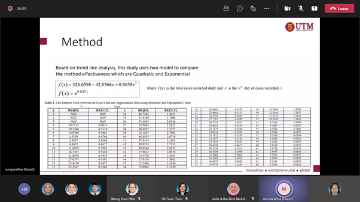
Research Talk by Invited Speaker from University of Malaya Malaysia
Bayesian Approach to Errors-in-variables in Count Data Regression Model
Date
12 February 2021 (Friday)
Time
3.00pm – 4.00pm
Platform
Microsoft Teams
Speaker
Dr Adriana Irawati Nur bt Ibrahim
Organizer/
Co-organizer
Centre for Mathematical Sciences (CMS)
Department of Mathematical and Actuarial
Sciences (DMAS)
Abstract:
|
Date |
12 February 2021 (Friday) |
|
Time |
3.00pm – 4.00pm |
|
Platform |
Microsoft Teams |
|
Speaker |
Dr Adriana Irawati Nur bt Ibrahim |
|
Organizer/ Co-organizer |
Centre for Mathematical Sciences (CMS) Department of Mathematical and Actuarial Sciences (DMAS) |
Abstract:
In many applications and experiments, data sets are often contaminated with error or have mismeasured covariates. Measurement error, when not corrected, would cause misleading statistical inferences and analysis. When at least one of the explanatory variables in the regression model is measured with error, Errors-in-Variables (EIV) model can be sued to examine the relationship between the outcome variable and the unobserved explanatory variables (also known as covariates or exposures) given the observed mismeasured explanatory variables (also known as surrogates). Therefore, our goal is to examine the relationship between these variables by applying the Bayesian formulation to the EIV model. We extended the flexible parametric approach, which uses flexible distributions, to other count data regression models such the Poisson and negative binomial regression models. For computational purposes, Markov chain Monte Carlo techniques were applied. Simulation studies were then conducted to investigate the performance of the proposed approach. The results showed that the approach worked well and was able to estimate the true regression parameters consistently and accurately.
Thank you for the interesting sharing!

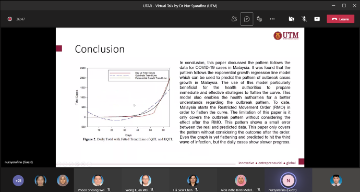
Research Talk by Invited Speaker from Universiti Putra Malaysia
Statistical Downscaling Projecting Future Climate and Its Applications on Health Impact Study
Date
5 February 2021 (Friday)
Time
10.30am – 11.30am
Platform
Microsoft Teams
Speaker
Dr Syafrina Abdul Halim
Organizer/
Co-organizer
Centre for Mathematical Sciences (CMS)
Department of Mathematical and Actuarial
Sciences (DMAS)
Abstract:
|
Date |
5 February 2021 (Friday) |
|
Time |
10.30am – 11.30am |
|
Platform |
Microsoft Teams |
|
Speaker |
Dr Syafrina Abdul Halim |
|
Organizer/ Co-organizer |
Centre for Mathematical Sciences (CMS) Department of Mathematical and Actuarial Sciences (DMAS) |
Abstract:
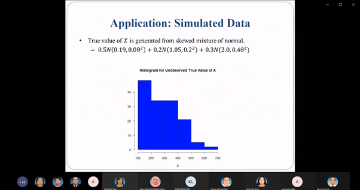
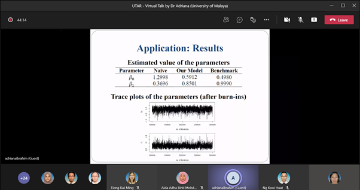
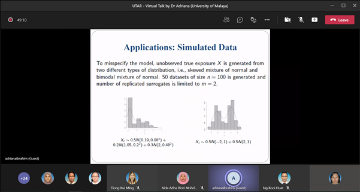
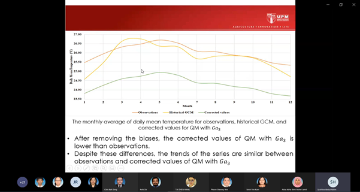
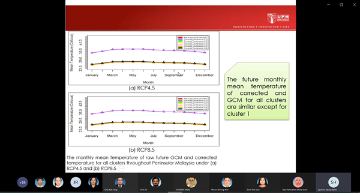
Climate change is one of the greatest challenges for water resources management. Intensity and frequency of extreme weather events such as rainfall and temperature are increasing due to enhanced greenhouse gas effect caused by climate change. A lot of research has been done in developing innovative methods for assessing the impacts of climate change. Global Climate Model (GCM) outputs are very essential in understanding the climate change as GCM may provide the information of historical, current and future climate to the researchers. A global climate model (GCM) is a complex mathematical representation of the major climate system components (atmosphere, land surface, ocean, and sea ice), and their interactions. Earth’s energy balance between the four components is the key to long-term climate prediction. However, due to their coarse resolution and the presence of large systematic biases in the GCM relative to observational datasets, statistical downscaling is widely applied to overcome the weaknesses. This presentation will introduce one of the statistical downscaling models and its application on the health impact study.
Thank you for the wonderful sharing!




The 16th IMT-GT International Conference on Mathematics, Statistics, and their Applications (ICMSA 2020)
23 & 24 November 2020
For more news/pictures on ICMSA 2020, please refer to:
https://news.utar.edu.my/news/2020/Dec/01/02/02.html

Wonderful speech by the President of UTAR, Ir Prof Dr Ewe Hong Tat
MOU Signing Ceremony between UTAR and Universitas Syiah Kuala, Indonesia

ICMSA 2020's Participants

Python Workshop

Excel Workshop
Research Talk by Invited Speaker from Universiti Teknologi Malaysia
Complex Model, Big Data Analytics, Huge Simulation and Performance Evaluation on High-Performance Computing Platforms
Date/day | 22 October 2020 / Thursday |
Time | 2.00 pm – 3.00 pm |
Venue |
Microsoft Team |
Speaker | Assoc
Prof Dr Norma Alias
|
Organizer/co-organizer | Centre for Mathematical Sciences Department of Mathematical and Actuarial Sciences (DMAS) |
Talk : Complex Model, Big Data Analytics, Huge Simulation and Performance Evaluation on High-Performance Computing Platforms
Abstract:
Some grand challenge applications have been explored, evaluating, and demonstrating the application of high-performance computing (HPC). The problem of data analysis and simulation are too large, too complex, or too time-consuming can be solved by using HPC. Simulation of highly complex models requires a high volume Tflops up to Pflops, variety, and velocity of data characterized. It is involved in fundamental theory, complex analysis, data transformation, multi-data studies, large-scale independent, and dependent parameters. A powerful simulation platform can cut processing time to shorten design cycles. Big data analytics such as machine, deep, or extrema learning ability to do manipulation, management, evaluation of large masses of data, and analysis of parallel computational models. Some performance indicators will be highlighted on application performance analysis environment across all HPC platforms, digital design, data visualization, prediction, and decision making driven by the big data phenomenon.

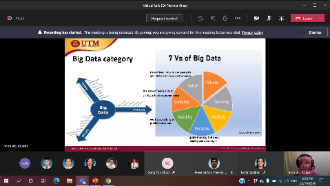
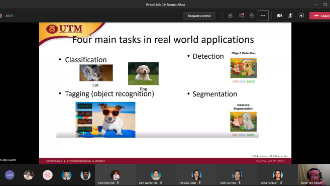
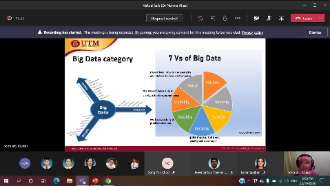
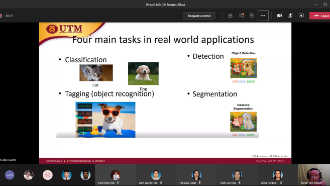
Industrial Talk by Invited Speaker from Monash University (Malaysia)
Research Activities on Dynamic Traffic Modelling
Date/day | 25 August 2020 / Tuesday |
Time | 2.00 pm – 3.00 pm |
Venue |
Microsoft Team |
Speaker |
Dr Susilawati |
Organizer/co-organizer | Centre for Mathematical Sciences Department of Mathematical and Actuarial Sciences (DMAS) |
Talk : Research Activities on Dynamic Traffic Modelling
Biodata of Speaker:
Dr. Susilawati received her Master's and Doctorate degrees in Transportation Engineering from the University of South Australia in 2007 and 2012. Before joining Monash, she worked in multinational consulting firms as a spatial analyst in Indonesia and Australia. Her research interests are mainly on dynamic transport planning and modeling that consider the stochastic nature of traffic demand and road capacity to create reliable transport systems. She is a PI of two FRGS on sustainable and intelligent transport and co-PI several multidisciplinary projects on smart city and active mobility. In 2010, she was awarded the Inaugural Young Researcher Award by the Australian Road Research Board.
Description of Talk:
The rapid development of emerging technologies (i.e., intelligent transport systems, big data, and autonomous vehicles) has shifted the focus of transport planning and management, from transport infrastructure construction to system-based transportation in order to provide reliable transport services and enhance accessibility. The current research on various issues related to dynamic transport planning and modeling that consider the stochastic nature of traffic demand and road capacity to assist in creating reliable and sustainable intelligent transport ecosystems will be presented. The application of an advanced statistical model, including the Generalized Linear Mix Model and Multilevel Hierarchical Bayesian model in the transport modeling, will be discussed as well.

Industrial Talk by Invited Speaker from Edustats Analytics
Risk Modelling and Simulation for SME
Date/day | 30 June 2020 / Tuesday |
Time | 10.00 am – 11.30 am |
Venue |
Microsoft Team |
Speaker |
Mr Harley Ooi |
Organizer/co-organizer | Centre for Mathematical Sciences Department of Mathematical and Actuarial Sciences (DMAS) |
Talk : Risk Modelling and Simulation for SME
Biodata of Speaker:
Harley Ooi is the consultant of Edustats Solutions, a leading provider in quantitative analysis consulting and training services. He participated in quantitative risk analysis consulting and has worked with various governments linked companies in Malaysia in the area of quantitative risk management. Mr Harley is also a co-trainer for Certified in Quantitative Risk Management (CQRM) and he has a good sense for predicting disrupting solutions and business models.
Description of Talk:
This talk has covered the following:
- Simulation/modeling techniques
- Desirable solutions
- Industrial case studies
- Risk identification
- Q&A

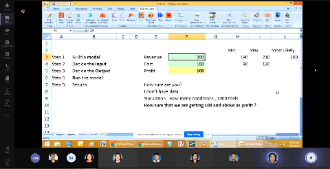
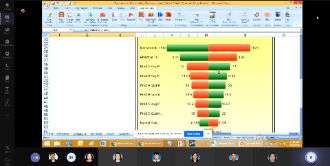
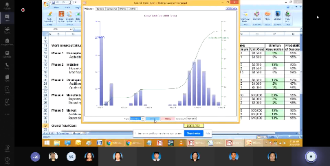
Talk by Invited Speaker from Universiti Tenaga National (UNITEN)
Multivariate Statistical Analysis of Water Quality Data in Subtropical Reservoir in Taiwan
Date/day | 11 March 2020 / Wednesday |
Time | 10.30 am – 11.30 am |
Venue |
KB209, UTAR (Sungai Long campus) |
Speaker |
Ir Dr Chow Ming Fai |
Organizer/co-organizer | Centre for Mathematical Sciences Department of Mathematical and Actuarial Sciences (DMAS) |
Talk : Multivariate Statistical Analysis of Water Quality Data in Subtropial Reservoir in Taiwan
ABSTRACT: The
evaluation and interpretation of the spatio-temporal pattern of surface water
quality is crucial for the assessment, restoration and protection of drinking
water sources. This study reports different multivariate statistical techniques
such as cluster analysis, factor analysis/principal component analysis (FA/PCA)
and discriminant analysis, which had been applied for 6 years (2005–2010) water
quality data set generated from 19 parameters at 14 different sites within the
Fei-Tsui Reservoir basin. Hierarchical cluster analysis grouped 14 sampling sites
into three clusters: high-, moderate- and low-pollution regions. This study
revealed that water release from the dam outlet will further increase the
concentrations of pollutants in the downstream river. PCA/FA did not result in
considerable data reduction, as it points to 13 parameters (68% of original 19)
required to explain the 72.8 % of the total variance in the water quality data
set. The varifactors obtained from PCA suggested that parameters responsible
for water quality variation were mainly related to mineral related parameters
(natural), nutrient group (non-point sources pollution), physical parameters
(natural) and organic pollutants (anthropogenic sources). Discriminant analysis
used only five parameters: water temperature, dissolved oxygen (DO), calcium,
total dissolved solids (TDS) and turbidity; and seven parameters: BOD, DO,
nitrate nitrogen, TDS, total alkalinity, turbidity and WT, to discriminate
between temporal and spatial with 88 and 90 % correct assignation,
respectively. This study illustrated the usefulness of multivariate statistical
techniques for designing the sampling and analytical protocol, analysis and
interpretation of complex data sets, identification of pollution
sources/factors, and provides a reliable guideline for selecting the priorities
of possible controlling measures in the sustainable management of Fei-Tsui
Reservoir basin.



Research Talk from Universiti Kebangsaan Malaysia (UKM) Speakers
Talk 1: Applications of Jump Diffusion Model in Finance & Actuarial Science
Talk 2: Risk Analysis of the Copula Dependent Aggregate Discounted Claims with Weibull Inter-arrival Time
Date/day | 7 February 2020 / Friday |
Time |
10am – 12pm |
Venue |
KB301, UTAR (Sungai Long campus) |
Speaker |
Talk 1: Dr. Siti Norafidah Mohd Ramli Talk 2: Pn. Sharifah Farah Syed Yusoff Al-Habshi
|
Organizer/co-organizer | Centre for Mathematical Sciences |
Talk 1: Applications of Jump Diffusion Model in Finance & Actuarial Science
Speaker: Dr. Siti Norafidah Mohd Ramli
ABSTRACT: We examine the effects of jump diffusion transition intensities on CDS and bond pricing, CDS pricing and a social benefit scheme consisting of life insurance, unemployment/disability benefits, and retirement benefits. To do so, we use a multi-states Markov chain with multiple decrement and later compare its performance with the celebrated Cox-Ingersoll-Ross model (1985). We then examine the performance of the model under the FGM and elliptical copulas. In the case of actuarial applications, we also examine the components of the prospective reserves by changing the relevant parameters of the transition intensities, which are the jump size, the average frequency of jumps as well as the diffusion parameters, assuming deterministic rate of interest.
Talk 2: Risk Analysis of the Copula Dependent Aggregate Discounted Claims with Weibull Inter-arrival Time
Speaker: Pn. Sharifah Farah Syed Yusoff Al-Habshi
ABSTRACT: We model the recursive moments of aggregate discounted claims, Z(t), assuming the inter-claim arrival time follows a Weibull distribution to accommodate overdispersed and underdispersed data set. We use a copula to capture the dependence structure between the inter-claim arrival time and its subsequent claim amount. We then use the Laplace inversion via the Gaver-Stehfest algorithm to solve numerically the first and second moments, which takes the form of a Volterra integral equation (VIE) of the second kind. We compute the average and variance of the aggregate discounted claims under the Farlie-Gumbel-Morgenstern (FGM) copula and conduct a sensitivity analysis on the first moment with various Weibull inter-claim parameters and claim-size parameters. The comparison between the equidispersed, overdispersed and underdispersed counting processes shows that when claims arrive at times that vary more than is expected, insured lives can expect to pay higher premium, and vice versa for the case of claims arriving at times that vary less than expected. Using a wider range of dependency as in Frank and Heavy Right Tail (HRT) copula, we would expect greater impact on the value of moments as opposed to under weaker dependency as in FGM copula.



Research Talk
Talk 1: The Use of Exploratory Structural Equation Modelling (ESEM) in Questionnaire Validation
Talk 2: Tracking Operation Status of Machines through Vibration Analysis using Motif Discovery
Date/day | 13-Jan-2020 |
Time | 12 noon - 1 pm |
Venue | D121, UTAR Perak Campus |
Speaker | Ms Kavitha Subramaniam, Mr Lee Yon Qing (represent
Dr Beh Woan Lin) |
Organizer/co-organizer | Centre for Mathematical Sciences |
Talk 1: The Use of Exploratory Structural Equation Modelling (ESEM) in Questionnaire Validation
By: Ms Kavitha Subramaniam (Lecturer, UTAR)
Synopsis: Confirmatory Factor Analysis (CFA), an application of Structural Equation Modelling (SEM), is currently considered as the gold standard analysis to identify structural validity of questionnaires. This is because the techniques has many advantages as compared to the Exploratory Factor Analysis (EFA) such as its ability to measure suitability of a proposed model (questionnaire structure) by providing various fit indices, enabling comparison of the structure across groups (Measurement Invariance), measuring the latent variable and so on. Some researchers argue that the underlying assumptions for CFA are overly restrictive and consequently the result obtained from the CFA analysis are questionable. The Exploratory Structural Equation Model (ESEM), which is a hybrid between the CFA and EFA was proposed as a potential alternative to study structural validity. The ESEM enables exploratory analysis and at the same times provides measures of the fit of the model. Existing literatures provide mixed evidence on whether the ESEM can replace the overly restrictive CFA / SEM. The use of ESEM in analytics, its potential in questionnaire validation and additional information obtainable when performed together with SEM will be discussed.
Talk 2: Tracking Operation Status of Machines through Vibration Analysis using Motif Discovery
By: Mr Lee Yon Qing (Undergraduate Student, UTAR)
Synopsis: Industrial revolution 4.0 is inevitable for developing countries and created an urgency for many small and medium enterprises (SME) manufacturers to modernize their operations. Unfortunately, the process of modernization is expensive and it may not be justifiable for SMEs. This work is part of our existing effort in developing retrofitting sensors solution to help in reducing the cost and risk of SMEs moving towards Industry 4.0. This work focuses on tracking operation of machine through vibration data. Vibration analysis is not new and there are many existing works especially in the area of machine condition monitoring. This work is different from machine condition monitoring because the aim of this work is to track operation status of machines. The operation status of machines are crucial for manufacturers to manage maintenance and estimate the throughput of their operation. However, the main challenge of tracking operation status is that there are no prior knowledge on the machine’s vibration. The success of Motif Discovery has provided an opportunity to distinguish and identify the operation status of a machine from its vibration with minimal interference to the machine’s operation. This work puts Matrix Profile to test; using 15 sets of vibration data from 2-speed (high and low speed) industrial fan and exhaust hood, with the period for each collection at 10 minutes. From the experimental results, this work showed that it is possible to track the operation status of a machine through its vibration data and the accuracy can be as high as 99%.



CMS Research Sharing Seminar 2019
Date/day | 29 November 2019 |
Time | 9:30 am - 4:00 pm |
Venue | IDK 5, 7, 8 (UTAR, Kampar campus) |
Speaker | Grant Holders and Postgraduate Students |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |



Research Talks:
Talk 1: Stochastic Control Application to Energy Tolling Agreements
Talk 2: Dependence in Binary Outcomes: A Quadratic Exponential Model Approach
Date/day | 27 November 2019 |
Time | 2:00 pm - 4:00 pm |
Venue | KB213 |
Speaker | • Dr Leyla Ranjbari • Dr Mahboobeh Zangeneh Sirdari |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |
Dr Leyla Ranjbari presented about the valuation of gas storage on finite horizon with focusing on intrinsic value of underground storage facilities. Assuming that the natural gas can be bought and sold on the spot market, the goal is to maximize the expected profit given operational constraints, in particular on the costly operating regime switches. In the first part of her presentation, the timing optionality of storage is formulated as an impulse stochastic control model reduced to solving an Optimal Switching Problem (OSP) with inventory. Then, an iterative Optimal Stopping Times (OSTs) is derived by applying the Bellman’s optimality principle on the OSP which is restricted to the number of allowed cycles. At the end of this theoretical section, martingale value functions for the OSTs using the Snell envelop of the discounted rewards are constructed. Then, Least-square Monte Carlo (LSM) regressions is constructed to solve the time discretized iterative OSTs. The idea of LSM is to simultaneously approximate the optimal switching times along all the simulated paths. The main difficulty is dealing with the path dependent inventory which is solved by generating independent uniform random terminal inventory level. The numerical results of two examples supports that the model is computationally efficient and robust. Moreover, the methodology is applicable to Optimal Switching Problems with Inventory problems, such as natural resource management.
In the second talk, Dr Mahboobeh Zangeneh Sirdari mentioned that in analyzing repeated measures data, we have to encounter the dependence in outcome variables at different times. This has been addressed mainly by the Generalized Estimating Equations which are marginal models and assume the dependence in outcomes. The quadratic exponential form employs different covariance structures. The research extended the form for transitions arising from repeated measures data and takes into account previous outcome as a covariate and thus reveals the order of dependence. The procedure can be extended further using higher order transitions and the test for higher order dependence can also be developed. The proposed extension of the quadratic exponential form model is illustrated with a set of depression data from elderly population and reveals first order dependence in the depression outcome.



Professional Talk by Invited Speakers
from
Universiti Putra Malaysia (UPM)
Date/day | 8 November 2019 |
Time | 2:30 pm - 4:30 pm |
Venue | KB213 |
Speaker | • Dr Chen Chuei Yee • Dr Yow Kai Siong • Dr Lim Fong Peng |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |
The first speaker, Dr. Chen Chuei Yee starts off her session with the title, “The Roles of Quasiminimizers in Improving Variational Principle in the Calculus of Variations”. She explained about the direct method in the calculus of variations which is a powerful abstract method for proving the existence of minimizers for variational problems and the regularity of the minimizer. In addition, Dr. Chen also presented the improvement made on the variational principle through the use of quasiminimizer due to its natural existence in different problems and global higher integrability.



Currency Hedging and Fair Premiums in Life Insurance Guaranty Schemes
Date/day | 20 August 2019 |
Time | 3:00 pm - 4:00 pm |
Venue | KB107 |
Speaker | Professor Bill Chang Shih-Chieh |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |




On Lifetime Data Modelling and Model Selection With Extended Weibull Distribution
Date/day | 19 August 2019 |
Time | 3:00 pm - 4:00 pm |
Venue | KB211 |
Speaker | Professor Xie Min |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |




Matrix Visualization: New Generation of Exploratory Data Analysis
Date/day | 19 August 2019 |
Time | 2:00 pm - 3:00 pm |
Venue | KB211 |
Speaker | Dr Chun-houh Chen |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |




Deep-Learning Solution to Portfolio Selection with Serially-Dependent Returns
Date/day | 16 August 2019 |
Time | 03:30pm - 04:30pm |
Venue | KB208 |
Speaker | Professor Wong Hoi Yin |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |
1) To offer a simple deep neural network architecture to portfolio selection problems.
2) To analyze the convergence properties of the proposed network under a general portfolio selection problem.
3) To show the convergence under some popular econometric models for asset returns, typically multivariate AR(1) and CCC - GARCH(1,1).
4) To present some numerical examples of the proposed deep learning solution which perform well for high-dimensional portfolios (up to 100 assets).



Technical Talk for Lanzhou Jiaotong University, China
Date/day | 5 August 2019 (Monday) |
Time | 11 am- 1 pm |
Venue | E010 (UTAR, Kampar campus) KB315 (UTAR, Sungai Long campus) |
Speaker | Encik Khairul Rizuan bin Suliman (speaker on 5/8/2019)
Ts Dr Teoh Lay Eng (speaker on 9/8/2019) |
Organizer/co-organizer | Faculty of Engineering and Green Technology, UTAR |
• The Overview and Development of Logistics Industry in Malaysia (speaker: Encik Khairul)
• Green Transport: From Planning to Operation (speaker: Ts Dr Teoh Lay Eng)
The students revealed that they gain a lot of insightful information not only from the talks but also their entire study tour in UTAR.


Preparation on the Application for Anugerah Akademik Negara (AAN) – Anugerah Pengajaran
Date/day | 12 July 2019 (Friday) |
Time | 10.00 am - 11.00 am |
Venue | D121, FSc, Kampar campus, UTAR. |
Speaker | Mr Chong Fook Seng (FSc, UTAR, Kampar) |
Organizer/co-organizer | Centre for Mathematical Sciences (CMS), |


Industry Talk by Alliance Bank
Date/day | 5 July 2019 (Friday) |
Time | 9.00 am - 5.00 pm |
Venue | KB313(9am-12pm), KB323(2pm-5pm) |
Speaker | Ms Heng Ai Lee (Senior Vice President, Head of Decision Management), Ms Hor Jiun Ru (Vice President, Coordinator of Decision Management Structure Internship Program) |
Organizer/co-organizer | Department of Mathematical and Actuarial Sciences |




Applications of Graph Theory in Data Science
Date/day | 24 June 2019 (Monday) |
Time | 9.30 am-11.30 am |
Venue | KA600D |
Speaker | Associate Professor Dr. Gobithaasan Rudrusamy |
Organizer/co-organizer | Centre for Mathematical Sciences (CMS), |


CMS Talk Series: “Effective Teaching Skills in Mathematics for Engineering Students”
Date/day | 24 May 2019 (Friday) |
Time | 10 am -11 am |
Venue | D121, FSc, UTAR Kampar |
Speaker | Mr Chong Fook Seng (FSc, UTAR, Kampar) |
Organizer/co-organizer | Centre for Mathematical Sciences (CMS), |




Robust Tensor Completion and Its Application
Date/day | 15-05-2019(Wednesday) |
Time | 3:30 pm - 4:30 pm |
Venue | KB520, UTAR Sg. Long |
Speaker | Prof Michael Ng Kwok Po (Hong Kong Baptist University)
|
Organizer/co-organizer | Department of Mathematics and Actuarial Sciences |




Workshop on Python in Statistical Modelling
Date/day | 22/04/2019 (Monday) - 23/04/2019 (Tuesday) |
Time | 8:30 am - 5:00 pm |
Venue | Ulugh Beg Computer Laboratory, Institute for Mathematical Research (INSPEM), Universiti Putra Malaysia |
Speaker | Mr. Chin Ching Herny (CMS, UTAR) Dr Mahboobeh Zangeneh Sirdari (CMS, UTAR) |
Organizer/co-organizer | Institute for Mathematical Research (INSPEM), |


CMS ONE-DAY RESEARCH SEMINAR
Date/day | 19-04-2019 (Friday) |
Time | 8:50 am - 5:00 pm |
Venue | KB110 |
Speaker | Prof Pooi Ah Hin, Dr Goh Yong Kheng, Dr Sim Hong Seng, Dr Chang Yun Fah, Prof Chia Gek Ling |
Organizer/co-organizer | Centre for Mathematical Sciences (CMS) |
1. To create a platform for researchers from different research group/background to present and share insightful findings in Mathematical Sciences.
2. To create an opportunity for researchers to explore new knowledge and to exchange research ideas.
3. To encourage multi-discipline collaborations among the researchers by expanding research networks.
4. To engage the latest research trends in Mathematical Sciences
The seminar started off with a warm welcome from Dr Yong Thian Khok (Director of Institute of Postgraduate Studies and Research, Universiti Tunku Abdul Rahman).
Then, we have our Invited Speaker, Prof Pooi Ah Hin to present on a topic titled “Applications of Latent Factors in Statistical Prediction” followed by Dr Goh Yong Kheng with “Financial Network Construction using Generative Adversarial Network” & “Build and Evaluate Your Algo Trading Strategy with Easystp Platform” topic, Dr Sim Hong Seng with a title “Gradient Method with Multiple Damping for Large-scale Unconstrained Optimization”, Dr Chang Yun Fah “On the Macroeconomic Determinants of the Housing Price Index in Taiwan: An Autocorrelated Unreplicated Linear Functional Relationship Model” and last but not least Prof Chia Gek Ling who presented a topic on “Symmetry in Magic Squares and Chinese Literature”. After a day of insightful event, the seminar ended at 5pm.








Understanding of Actuarial Sciences Studies and its Applications
|
Date/day |
25-03-2019 (Monday) |
|
Time |
10:00 am - 11:00 am |
|
Venue |
KB214 |
|
Speaker |
Great Eastern Life Insurance (Malaysia) Berhad: Mr Goh Chek Heong (Senior Group Sales Manager) Ms Sasa Tan Yuin Joo (Group Agency Manager) |
|
Organizer/co-organizer |
Department of Mathematics and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |



Actuarial Society of Malaysia (ASM)
New Council
Meeting
|
Date/day |
04-03-2019 ( Monday) |
|
Time |
02:00 pm - 04:00 pm |
|
Venue |
KB 803 |
|
Speaker |
Ms. Sophia Ch'ng Ms. Lim Shu Yi, Mr. Soo Wei Chern Ms. Macy Lee
|
|
Organizer/co-organizer |
Department of Mathematics and Actuarial
Sciences (DMAS) |
The Actuarial Society of Malaysia (ASM) was founded on 5th October 1978. ASM are the only representative body for the actuarial profession in Malaysia, and provide a platform for members of the actuarial profession to raise and discuss technical issues and public interest related to the actuarial profession; to communicate such issues to relevant parties including the public, industry regulators and corporate stakeholders; to provide educational support to actuarial students and professional development to qualified actuaries; and to provide space for members of the profession to build relationships. On 20th October 2003, ASM became a Full Member Association of the International Actuarial Association. ASM is committed in working to become a full-fledged professional body with recognised examinations and accreditation system. The meeting commenced at 2pm. Ms. Sophia Ch'ng, Ms. Lim Shu Yi, Mr. Soo Wei Chern and Ms. Macy Lee were given tokens of appreciation at the end of the meeting.
Thank you and All the Best!

METLIFE ACTUARIAL INDUSTRY TALK
|
Date/day |
26-02-2019 (Tuesday) |
|
Time |
8:30 am - 10:00 am |
|
Venue |
KB 209 |
|
Speaker |
Tim Braswell Stephanie McGovern Nick Walters. Des Thomas Rick Butler Micky Kuo
|
|
Organizer/co-organizer |
Department of Mathematics and Actuarial
Sciences (DMAS) |
MetLife is one of the world's leading financial services companies which includes providing insurance, annuities, employee benefits and asset management to help its individual and institutional customers navigate their changing world. MetLife is building a Finance Center of Excellence (CoE) in Kuala Lumpur, Malaysia to support the finance teams based across Asia in markets like Japan, Korea, Australia, Hong Kong etc. The event starts off by an introduction about MetLife, its departments as well as the various important responsibilities they hold. An interview session which is part of the recruitment drive was then held after the talk.
Thank you METLIFE for the Opportunity!




IAP Talk For Final Year Students
|
Date/day |
9 Jan 2019 (Wednesday) |
|
Time |
2:30 pm - 4:00 pm |
|
Venue |
KB100, UTAR (Sungai Long campus) |
|
Speaker |
Mr. Kelvin Hii Chee Yun, Vice President – Actuarial at MSIG Insurance (Malaysia) Bhd |
|
Organizer/co-organizer |
Department of Mathematics and Actuarial Sciences (DMAS) Centre for Mathematical Sciences (CMS) |
This talk is organized to provide advice to students on methods to prepare themselves for the working world in the final trimester before graduating. These advice were given by one of the most important people from the actuarial world, Mr. Kelvin Hii. Among the preparations mentioned, they include improving soft skills (e.g. interview tips), preparing for professional exams (e.g. SOA exams) strategy and widening their knowledge on the latest trend in the actuarial industry (e.g. the development in the insurance industry) such as the implementation of IFRS and MFRS accounting standards. It was a very fruitful talk given by Mr. Kelvin Hii especially to the final year students. They gained many insightful knowledge and broadening ideas in order to be ready for the tough challenges that lies ahead of them in future.
Thank you Mr. Kelvin Hii!


